如何在Python中使用Scikit-learn分类数据

在我们开始之前:本Python教程是我们的Python包教程系列.
在有监督机器学习(ML)中,分类是基于预定义的已被“标记”的数据类别预测数据的类别或类别的过程。
- 标记数据是已经分类的数据
- 未标记数据是尚未标记的数据
有关标签数据的更多信息,请参阅:如何在Python中为机器学习标记数据
类型的分类
主要有两种分类:
- 二元分类-根据离散或非连续值(通常是两个值)对数据进行排序。例如,一项医学测试可以将病人分为患有某种特定疾病的人和没有患病的人。
- 多层次分类-将数据分类为三个或更多类。例如,将病人分为有肾、肝、肺或膀胱感染症状的人。
如何使用Scikit-Learn进行分类
您可以使用scikit-learn执行分类使用其众多的分类算法(也称为分类器),包括:
- 决策树/随机森林-决策树分类器具有分类为树中的节点或分支的数据集属性。随机森林分类器是一个元估计器,它适合决策树的森林,并使用平均值来提高预测精度。
- 再邻居(资讯)-一种简单的分类算法,其中K为训练记录数的平方根.
- 线性判别分析- e为每个类估计一组新的输入的概率。
- 逻辑回归-一个有输入变量(x)和输出变量(y)的模型,输出变量(y)是一个离散值,1(是)或0(否)。
- 朴素贝叶斯-一组基于简单贝叶斯模型的分类器,相对快速和准确。贝叶斯理论探讨了概率和可能性之间的关系。
- 支持向量机-一个具有相关学习算法的模型,分析数据进行分类。也被称为支持向量网络。
有关SciKit-Learn的更多信息,以及如何安装它,请参阅:
如何使用k近邻运行分类任务
在本例中,KNN分类器用于训练数据和运行分类任务。
#导入该示例所需的库和类:from sklearn从sklearn导入train_test_split。从sklearn导入StandardScaler。neighbors从sklearn导入KNeighborsClassifier。metrics import classification_report, conficon_matrix import pandas as pd # import dataset: url = " iris.csv " # Assign column names to dataset: names = ['sepal-length', 'sepal-width', ' petals -length', '花瓣-width', 'Class'] # Convert dataset to a pandas dataframe: dataset = pd。read_csv(url, names=names) #使用head()函数返回前5行:iloc(:,: 1)。y = dataset。iloc(: 4)。#将数据集分割为随机的列车和测试子集:X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) #通过去除均值和单位方差缩放来标准化特征:scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test) #使用KNN分类器来适合数据:classifier = KNeighborsClassifier(n_neighbors=5)分类器。使用分类器预测y数据:y_predict = classifier. Predict (X_test) #打印结果:Print (confusion_matrix(y_test, y_predict)) Print (classification_report(y_test, y_predict))
看如何使用KNN分类器来训练和分类数据:
如何用朴素贝叶斯进行分类
在这个例子中,一个朴素贝叶斯(NB)分类器用于运行分类任务。
#导入这个例子中需要的数据集和类:数据集从sklearn导入load_iris。导入高斯朴素贝叶斯分类器:从sklearn。naive_bayes从sklearn导入高斯annb。metrics import accuracy_score # Load dataset: data = load_iris() #组织数据:label_names = data['target_names'] feature_names = data['target'] features = data['data'] #打印数据:Print (label_names) Print ('Class label = ', labels[0]) Print (feature_names) Print (features[0])
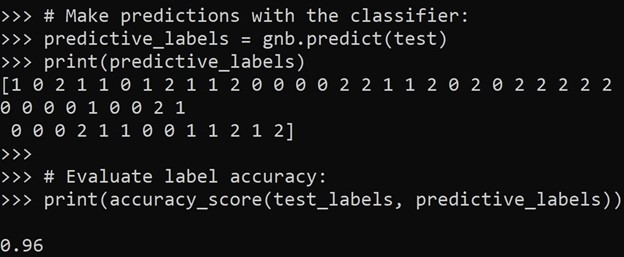
#将数据集分割为随机的train和test子集:train, test, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=42) #初始化分类器:gnb = GaussianNB()#使用分类器进行预测:predictive_labels = gnb.predict(test) print(predictive_labels) # Evaluate label (subsets) accuracy: print(accuracy_score(test_labels, predictive_labels))
图1所示。分类器标签预测和准确性:
分类与回归
分类和回归的主要区别在于分类输出变量是离散的,而回归输出变量是连续的。
有关回归的信息,请参阅:如何在Python中运行线性回归
下面的教程将逐步指导你如何使用机器学习Python包:
获取一个Python版本,用Scikit-learn、NumPy、pandas和其他流行的ML包预编译
ActivePython是适用于Windows、Linux和Mac的受信任的Python发行版,预绑定了用于机器学习的顶级Python包——可免费用于开发使用。
使用ActivePython预编译一些流行的ML包
机器学习:
- TensorFlow(基于神经网络的深度学习)*
- scikit-learn(机器学习算法)
- keras(高级神经网络API)
数据科学:
- 熊猫(数据分析)
- NumPy(多维数组)
- SciPy(使用numpy的算法)
- HDF5(存储和操作数据)
- matplotlib(数据显示)
点击这里获取用于Windows、macOS或Linux的机器学习ActivePython。
为什么使用ActivePython而不是开源Python?
虽然Python的开源发行版可能对个人来说是令人满意的,但它并不总是能满足大型组织的支持、安全性或平台需求。
这就是企业选择ActivePython的原因,因为他们需要数据科学、大数据处理和统计分析。
ActivePython预先与数据科学家需要的最重要的软件包捆绑在一起,是预编译的,因此您和您的团队不必浪费时间配置开源发行版。您可以将精力集中在重要的事情上——花更多的时间针对大数据源构建算法和预测模型,而在系统配置上花更少的时间。
ActivePython与开源Python发行版100%兼容,并提供您的组织所需的安全和商业支持。
使用ActivePython,您可以探索和操作数据,运行统计分析,并提供可视化,以便更快地与业务用户和高管共享见解——无论您的数据位于何处。
下载activeppython社区版开始或联系我们了解有关在组织中使用ActivePython的更多信息。
推荐阅读
机器学习的Python备忘单:聪明的提示和技巧