
文本生成是应用机器学习(ML)最常见的例子之一。不断进化的算法和大量可用的文本数据,使我们能够训练模型,试图捕捉上下文或模仿他人之前的工作。通过这种方式,ML已经被用来做从新闻文章到短篇故事到整部小说的所有事情。不幸的是,它们中的许多显然是糟糕的写作例子,这主要是因为ML例程经常生成无意义的句子,并生成结构一致性差的长格式文档。
有趣的是,这些缺点实际上在写诗时对ML有利,因此,歌词更注重在读者/听众中产生情感反应,而不是智力反应。给定一组输入关键字,ML驱动的歌词生成器将生成一首不会获奖的诗s、 但很可能会引起读者的反应,即使只是嘲笑它的荒谬。
在这篇文章中,我们将使用ML来构建一个程序,它将自动生成歌词.为此,我们将遵循以下步骤:
- 下载培训数据歌词和诗歌
- 清理和合并数据
- 创建一个递归神经网络(rnn)
- 估计结果
在你开始之前:安装我们的歌词生成器即用的Python环境
开始构建你的Twitter Bot最简单的方法是安装我们的歌词生成器Python环境它包含Python的一个版本和你需要的所有包。
为了下载现成的歌词生成器Python环境,您需要创建一个ActiveState平台帐户。只需使用您的GitHub凭据或电子邮件地址进行注册。注册很简单,它为您打开了ActiveState平台的许多好处!188bet金宝搏备用
或者你也可以用我们的国家工具安装此运行时环境。
对于Windows用户,在CMD提示符下运行以下命令,自动下载并安装我们的CLI, State工具和歌词生成器运行时到虚拟环境中:
powershell -Command "& $([scriptblock]::Create((New-Object Net.WebClient).DownloadString('https://platform.activestate.com/dl/cli/install.ps1')) -activate-default Pizza-Team/Lyrics-Generator"
适用于Linux用户,运行以下内容以自动下载并安装我们的CLI,状态工具以及歌词生成器运行时进入虚拟环境:
——activate-default Pizza-Team/Lyrics-Generator .sh <(curl -q https://platform.activestate.com/dl/cli/install.sh
1 .导入抒情诗资料
好的,首先我们需要得到一些训练数据,这些数据应该包括实际歌曲的歌词。
有几个可用的数据集,包括:
- 百万歌曲数据集,它包括单词、标签、相似性、体裁和许多其他特性,分布在几个文件中
- MusicMoodDataSet,其中包含大约10,000首标记为情感分析的歌曲
- Genius.com,特别是LyricsGenius包
但是每个数据工程师都知道,最好的代码是不需要自己维护的代码MusicOSet数据集,它将来自多个来源(包括Genius.com)的数据聚合成CSV。
但为了提高押韵的质量我们的ML例程将产生,我们也可以添加一些诗歌诗歌的基础通过卡格尔.这个数据集(可作为CSV文件使用)包含约1.4万首诗,包括作者,在某些情况下,还有与诗歌相关的标签。我们的想法是将两种来源结合起来,以增加获得一些有用经文的机会。
下面的代码将导入我们的两个数据源,并初始化一个字符串转换器,在训练前从文本中清除标点符号:
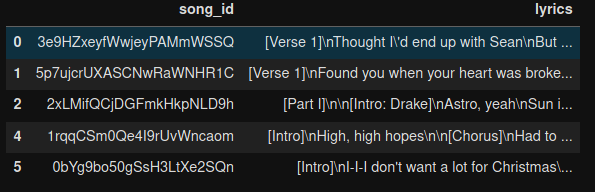
进口木卫一进口OS.进口SYS.进口细绳进口numpy.作为NP进口熊猫作为PD.从tensorflow进口凯拉斯从__未来__进口print_function从tensorflow.keras.models.进口顺序从sklearn.model_selection进口train_test_split.从tensorflow.keras.callbacks进口LambdaCallback、ModelCheckpoint EarlyStopping从tensorflow.keras.layers进口密集型、辍学型、激活型、LSTM型、双向型、嵌入型翻译器=str..maketrans ('','',string.punctuation)df = pd.read_csv(“/数据/歌词.csv”,9月="\ t")df.head()pdf=pd.read\u csv('./data/poetryfoundationdata.csv',quotechar='“')pdf.head ()
歌曲歌词的结果显示了大约20,000个可用歌曲:
2–清理数据
对数据的快速探索表明,每首歌的歌词都包含一些元标签的形式[标签]文本[/标签].考虑到这一点,我们可以将每首歌的引言、主歌和副歌分开,只选择前四个主歌(如果有的话)和副歌。我们可以应用一个简单的函数来处理每首歌,以便拆分每一段歌词,并将结果文本加入到单个文本中:
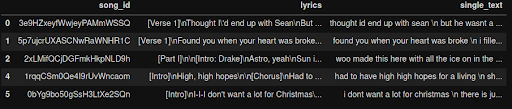
defsplit_text(x):text = x [“歌词”]sections = text.split('\\n\\不)键= {“第1节”:np.nan,“第2节”: np.nan,“第3节”: np.nan,“第4节”: np.nan,'合唱': np.nan}歌词=str.()single_text = []res = {}为年代在里面部分:关键= s [s.find ('[')+1:s.find(']')].strip()如果':'在里面关键:key=key[:key.find(':')]如果钥匙在里面钥匙:single_text + =[害处().replace (“(”,'')。代替(')','') .translate(翻译)为x在里面s [s.find(']')+1:]拆分('\\不)如果Len.(x) >1]res (“单一文本”] ='\ n'.join(单个文本)回来PD.Series(RES)df = df。加入(df.apply (split_text,轴=1))df.head()
结果是一个新的列,在一行文本中包含干净的歌词。我们保留了新的行分隔符\ n为了训练模型在需要时开始新的生产线:
清洁POEMS文本的功能更简单,并且可以在单行代码中应用:
pdf[“单一文本”pdf] = [“诗”苹果(lambda.x:'\ n'.translate .strip . join ([l.lower()()(翻译)为l在里面x.splitlines()如果Len.(l) >0]))pdf.head ()
结果是一个与歌词数据帧同名的小写列,没有标点符号。现在,我们将两个数据帧连接成一个单独的数据帧,我们将使用它来训练模型:
sum_df = pd.dataframe(df [“单一文本”] )sum_df = sum_df.append(pd.dataframe(pdf [“单一文本”)))总分(原地=符合事实的)
3、建立递归神经网络(RNN)
回想一下,神经网络是专门识别模式的算法。基本神经网络包括:
- 一个输入层
- 根据所提供的例子学习的函数
- 输出层
学习过程包括最小化计算输出(即。,即ml生成的歌词)和目标输出(即。,our imported lyric/poetry data) for the same input (ie., the same seeded keywords) in a recurrent way.
在最基本的神经网络中,这些算法的输入都是固定大小的向量,计算这些向量得到固定大小的结果。例如,对于图像分类,一个单一的输入向量(图像)产生一个单一的概率向量(即。例如,图像可能是马或狗)。
更复杂的神经网络使您能够解决需要一系列向量作为输入和/或输出的问题。示例包括:
- 图像标题,其中输入图像是一个单一的向量,但输出是一个文本向量序列(即。,图像的描述)
- 情绪分析,其中输入是文本向量的序列,但输出是概率的单个向量(即,评论为正为阳性的可能性。
- 文本翻译,其中输入是某种语言的文本向量序列,输出是另一种语言的文本向量序列
- 同步视频字幕,其中输入是视频帧向量序列,输出是文本向量序列(即视频每帧的字幕)。
RNN提供与输入和学习功能组合的内部状态,以产生新状态。这意味着RNN是有状态的,并且可以用于解决包括作为输入的向量序列的问题。在我们的例子中,我们希望使用RNN来创建语言模型。
语言模型是一个词序列的概率分布。它可以用来获得给定一个词序列的条件概率。例如,给定一个词序列(“我们”,“我”、“看”、“是什么”,“春天”,“是”,“喜欢”,“上”)该模型可以计算出木星对巴黎作为序列中的下一个单词。
创建歌词生成器的一种方法是培训一个RNN,以基于从歌曲和诗歌中提取的示例来预测句子中的下一个单词。要采取这种方法,我们将首先需要:
- 过滤我们的DataSet for Common与罕见单词
- 创建一个由固定长度的单词组成的句子训练集
text_as_list = []频率= {}不寻常的词=集()MIN_FREQUENCY =7最小顺序=5batch_size =.32.defExtract_Text.(文本):全球的text_as_list.text_as_list + = (w为w在里面text.split('')如果w.strip () ! =''或者w = ='\ n']总和[“单一文本”] .Apply(Extract_Text)打印(“总的话:”,Len.(text_as_list)))为w在里面文本作为列表:频率[w] =频率。重点(w,0)+1不寻常的词=集([钥匙为钥匙在里面频率.键()如果频率(例子)< MIN_FREQUENCY])单词=排序(集([钥匙为钥匙在里面频率.键()如果频率(例子)> = MIN_FREQUENCY]))num_words =Len.(字)Word_indices =.dict((w,我)为我,女在里面列举(字))indices_word =dict((我,w)为我,女在里面列举(字))打印(“用不到的话。{}外观:{}'.format(min_frequency,Len.(andermon_words))))打印("多句话,{}外观:{}'.format(min_frequency,Len.(字)))valid_seqs = []结束语_seq_words=[]为我在里面范围(Len.(text_as_list) - MIN_SEQ):end_slice = i + MIN_SEQ +1如果Len.(集(text_as_list [i: end_slice]) .intersection (uncommon_words)) = =0:有效_seqs.append(text_as_list [i:i + min_seq])结束顺序单词。追加(文本作为列表[i+MIN顺序])打印('有效的大小序列{}:{}'.format(min_seq,Len.(valid_seqs)))X_序列,X_测试,y_序列,y_测试=序列测试分割(有效序列,结束序列字,test_size.=0.02,随机状态=42.)打印(X_系列)[2:5])
我们还需要一些支持功能:
- 一个生成器函数,用于将训练数据集流式传输到模型,以避免出现“内存不足”错误。您可能需要查看有关生成器和Python包keras我们将使用。
- 从keras样本中提取的两个函数,在每个训练阶段结束时对结果进行采样
#数据发生器适合和评估def发电机(句子,next_word_list,batch_size.):指数=0虽然符合事实的:x=np.零((批次大小,最小顺序),dtype=np.int32)y = np.zeros((batch_size),dtype=np.int32)为我在里面范围(批量大小):为t w在里面列举(句子列表[索引]Len.(sentence_list)]):x [i,t] = word_indices [w]Y [i] = word_indices[next_word_list[index % .Len.(stank_list)]]Index = Index +1产量X,Y.# keras-team/keras/blob/master/examples/lstm_text_generation.py函数def样本(仅仅,温度=1):#从概率数组中采样索引的辅助函数仅仅= np.asarray(仅仅).astype (“float64”)Preds = np.log(Preds) / temperatureexp_preds = np.exp(preds)exp_preds = exp_preds / np.sum(exp_preds)probas = np.random.multinomial(1仅仅,1)回来np.argmax (probas)defon_epoch_end.(纪元,日志):#在每个epoch末尾调用的函数。打印生成的文本。examplex_file.write('\ n-----在Epoch之后生成文本:%d\ n'%时代)#随机选择种子序列seed_index = np.random.randint (Len.(X_train + X_test))种子=(x_train + x_test)[seed_index]为多样性在里面[0.3,0.4,0.5,0.6,0.7]:句子=种子examplex_file.write(' - - - 多样性:'+str.(多样性)+'\ n')examplex_file.write('-----用种子生成:\ n“‘+''. join(句子)+'"\ n')examplex_file.write(''. join(句子)为我在里面范围(50.):x_pred = np.zeros ((1, MIN_SEQ))为T,Word.在里面列举(一句):x_pred [0, t] = word_indices[word]preds=模型预测(x_pred,冗长的=0)[0]下一个索引=样本(preds,多样性)next_word = indices_word [next_index]句子=句子[1:]stoud.append(next_word)examplex_file.write(”“+ next_word)examplex_file.write('\ n')examplex_file.write('='*80+'\ n')示例_file.flush()
最后,用一个简单的函数构建模型进行文本生成。我们将使用带有单词嵌入层的长短期记忆(RNN的一种变体)。的单词嵌入技术将类似含义的单词映射到预定义的矢量空间中的近距离的矢量。这种技术还提高了模型的训练速度,因为它以密集的方式代表单词。
的激活函数是网络决定一个节点是否被激活的方式。这引入了一种不同于线性回归模型的非线性行为:
defget_模型():打印(“构建模型…”)模型=顺序()model.add(嵌入)(input_dim=Len.(字),output_dim=1024))模型.添加(双向(LSTM(128.))))model.add(密集(Len.(字)))model.add(激活('softmax'))回来模型
培训代码根据准确度分数,使用“最佳”模型保存检查点。在每个时代结束时,一些样品写入examples.txt文件。每个示例都是使用一个称为温度,它模拟的是创造力当计算预测的下一个单词时,网络将允许自己。
在我们的例子中,我们将温度从0.3变化到0.7,并使用98%的例子作为训练集来训练我们的模型:
model = get_model()model.compile (损失=“稀疏分类交叉熵”,优化器=“亚当”,指标=['准确性'])file_path =“/检查点/LSTM-epoch{epoch:03d}-言语%d-序列%d-明弗尔%d-"\“损失{丢失:.4f}-行政协调会{准确性:.4f}-val_loss.{val_loss: .4f}-瓦卢行政区{val_accuracy: .4f}"%\(Len.(单词),MIN_SEQ MIN_FREQUENCY)检查点= ModelCheckpoint (file_path,班长=“准确度”,save_best_only=符合事实的)print_callback = lambdacallback(on_epoch_end.= on_epoch_end)early_stopping = EarlyStopping (班长=“准确度”,耐心=20.)Callbacks_list = [checkpoint, print_callback, early_stop]examples_file =打开('examplear.txt',“W”)批量发电机(批量,U型),steps_per_epoch=int(Len.(valid_seqs) / BATCH_SIZE) +1,时代=20.,回调=回调\u列表,validation_data=发生器(X_test y_train BATCH_SIZE),验证步骤=int(Len.(y_train) / BATCH_SIZE) +1)
4 .每个训练阶段的结果
过一段时间,我们的模型就会得出一些结果。注意,你肯定想在GPU上训练这些类型的模型以获得更快的结果。随着epoch迭代的进行,结果将得到改善。例如,以下生成的歌词是来自第二阶段不断升级的创造力水平的样本:
------在时代后生成文本:2——多样性:0.3-----使用种子生成:“哦,没关系,只是”哦,没关系,这就是我的方式我快回家了我正在回家家我找不到机会去发现你移动的方式哦,我的天,我的天,我的天,我的天,我的天,我的天——多样性:0.4-----使用种子生成:“哦,没关系,只是”哦,没关系,那只是我的方式,你给我的感觉这就是你的运动方式哦,你把我卡住了在里面街上而我却从未见过我得到了动作我有动作我得到了动作我有个动作我——多样性:0.5-----使用种子生成:“哦,没关系,只是”哦,没关系,这就是你给我的感觉这就是你的运动方式但我正在搬家的路上你爱我我不能结束你别说我是戒指他妈的艾伊,把钱都花掉了离开我——多样性:0.6-----使用种子生成:“哦,没关系,只是”哦,这就对了,这就是他们比这首歌更正确的方式那是巨人还是不是我的心,我的心不能让它走了永远不要做一个真正的人长长的时间我看到我有很多机会——多样性:0.7-----使用种子生成:“哦,没关系,只是”哦,没关系,那只是我的朋友告诉我你的头发在哪里另一个是我搞的在我身体的屋顶上作为如果你可以穿你的运动衫哦你不能带你美丽的家,我留下我一个哦,是的,是的我的宝贝================================================================.
将上述结果与从第20次迭代中获得的结果进行比较:
================================================================.-----在Epoch之后生成文本:19.——多样性:0.3-----使用种子生成:"你坐在这里吗"你就坐在酒吧里吗把它放进保险箱,看看它有多真实当你听到这个声音时,把它拍紧不等待makin你不是抱歉为你我总是在你出现的路上哦什么如果我做当你的脸感到——多样性:0.4-----使用种子生成:"你坐在这里吗"夏天你在这里是坐在的我只需要一个更多的射击在第二次毛巾我是一个梦想如果你不知道我的名字当我和你在一起时,我不碰不碰我不喜欢我只是控制因为我想这是因为我记得为第一个——多样性:0.5-----使用种子生成:"你坐在这里吗"你就坐在酒吧里吗放在火的边缘的天空中直到热量是尖锐的为你水晶我知道我想知道我不知道该怎么办你解决想要你知道的东西我们身体上的巨大年龄——多样性:0.6-----使用种子生成:"你坐在这里吗"你坐在这儿吗如果你不知道我有多喜欢你我知道我想和你一样我只是想去那个地方阅读在哪里在干燥的土地上和学校后面的星星站在我这边说站在我这边——多样性:0.7-----使用种子生成:"你坐在这里吗"你坐在这里吗告诉我你也有同样的感受有时你恨你的爱是的,我的两个家园呀呜呜呜呜呜呜呜呜呜呜呜呜呜呜呜呜呜呜呜呜呜呜呜呜ima购买它真实的吃饭开始坐在那里================================================================.
古老的格言“假装直到你做到”在这里是合适的,因为很明显,我们需要更多的迭代,在我们得到一些真正有用的歌词。
结论:使用ActivePython构建歌词生成器–更快、安全,更适合团队
训练一个RRN模型来生成模仿一堆输入示例的文本真的很有趣,而我们生成的歌词不太可能为我们赢得更多的关注普利策奖,RNN模型背后的概念和工具众所周知,允许我们只需几行代码生成一些快速的结果。但如果您希望您的歌词更好地模拟人类的产出,您将必须投入更多的时间和资源。
构建一个好的RNN和调优超参数是一项非常复杂的任务。在我们的例子中,我们选择使用长短期记忆RNN,但我们也可以尝试其他变体,比如自传,这是一种自动完成构建神经网络模型所需的许多任务的工具。文本回归样本表明,在给定序列的情况下,训练一个可以预测单词的模型是多么容易。另一个选择是尝试编写一个类似于微型模型的模型生成Pre-trained变压器(GPT)。或者您可以使用预先训练的模型GPT-2简单.
- 您可以在my中检查此模型的全部代码GitHub存储库.
- 要更快地开始,请安装我们的歌词生成器运行时环境它包含Python的一个版本和你需要的所有包。

使用ActiveS188bet金宝搏备用tate平台,您可以在几分钟内创建Python环境,就像我们为此项目构建的Python环境。你自己试试吧或者了解更多关于它的帮助Python开发人员的工作效率更高.